
Git is one of the important code management systems that is widely used. It is an essential tool for me. If it’s not being used in the project for which I work, I would leave the project.
What is a commit in Git
To make a feature, we need to add or change a lot of lines of code. There are lots of points to save the code on the way to the goal. Those save points are recorded in Git so that we can follow the history of the code.
The diff between the two save points is called “commit”. In other words, commit is a unit of code change. While we develop something, the steps look like the following.
- Add a function
- Write unit tests
- Do a “commit” to save the change
- Rename some variables in the function
- Do a “commit”
- etc…
We repeat these steps during our development. If the feature works and the code is ready, we “push” the branch to upload it to the remote server so that other developers can review the code. If one of the commits is not necessary, we can easily revert the change by “git revert”. We don’t have to do it manually.
You might want to check this post as well if you want to know git commands.

Git Commit messages make a change history
A commit has a message. If a long message is given to it in VSCode, a warning message is shown. A commit message should be short enough and clear because it’s easier to follow the history. I guess many products for git show the history with the same height. The following image is from Github.
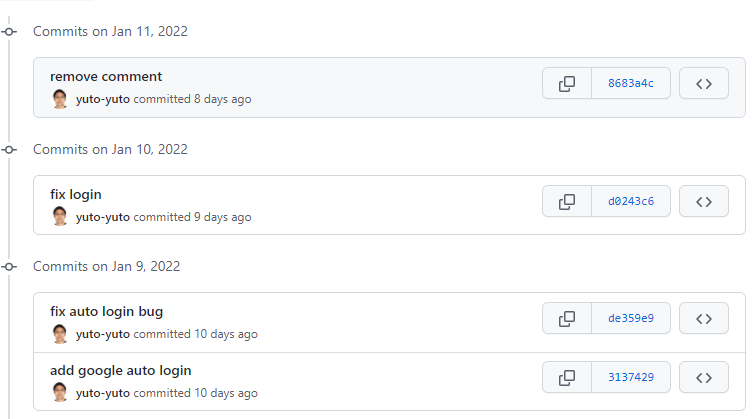
It doesn’t include a long message, so I don’t know how it shows a commit if it has a too long message to show on a line. It might cut the message if it is long. Anyway, no one wants to read a long message.
After the code change, it is normally reviewed by other developers. A good commit message can help reviewers follow the code. It’s hard to follow the history if messages are like “fix”.
We sometimes want to know why it is implemented in this way. In this case, git history is helpful to check the code author. If the author wrote the reason in the commit, it might be enough to understand the code. If not, we can directly ask the author about it but it takes additional time.
How to write a commit message
It is not easy to write a short and clear enough message but if we have a standard, it can improve the message.
Using Prefix
I’ve never used prefixes but I think it is helpful because it forces a developer to focus on one thing at a time. The number of prefixes depends on the team members. It should be discussed within the team.
If we have the following prefixes, we can’t put both new features and bug fixes into one commit. It must be split by two commits.
add: New feature, function, file
fix: Bug fix
update: Behavior change,
docs: Changes only for docs
refactor: Refactoring that does not include new feature, bug fix
test: Add/change testAdd a reason for the change
It’s easier for reviewers to understand the code if a reason for the change is written in the commit message.
Example
fix: function AAA for something - TICKET-1234
update: function BBB to improve performance
update: function CCC for handling invalid inputIf we need to write a reason for the commit, it needs to be small enough because it’s hard to write a reason if the commit is big and contains many changes. It’s a good habit to focus on one thing at a time and consider the commit size.
No good/clear reason comes up for some changes, e.g. defining a model, view, etc… In this case, it’s ok not to write the reason if the message is understandable for people.
In the case the task is managed by a system like Redmine or JIRA, it’s not necessary to write the reason in detail. It depends on the project how detailed the commit message should be.
What if a single commit is big
Some developers might think it’s enough to be able to save the code points and say “I want to implement this, this, and this features at the same time.”. In another case, “I don’t know how big the feature will be, and what functions are necessary for it. I’ve done only a single commit because I have realized that I hadn’t done any commit yet.” What happens in this case?
cherry-pick cannot be used
When the pull request (PR) is big, it takes a while to review it. If reviewers leave a bunch of feedback, we need to fix those issues. In this case, the PR might keep open for a week. If the build fails only on a CI server for an unknown reason, we need to spend more time on it. In the meanwhile, another developer completed his task and took the next one but he needed to use the same functionality that is reviewed at the moment.
We can’t wait for the PR and want to start implementing the new feature. What we want to do in this case is git cherry-pick that takes the commits from another branch and applies them to the current branch. If the commits are separated in a proper unit, we can use cherry-pick to apply the code. However, cherry-pick can’t be used if there is only a single commit that contains everything because unrelated code is also taken. In this case, we need to read the code and manually copy and paste them. This is not so good.
It would be nice if it’s possible to avoid this case but sometimes not. I’ve actually experienced this. The reviewee was on 2 weeks’ vacations then.
Hard to find a bug
To add a feature, the development cycle is something like this.
- Add code
- Run the app to check if it works. It doesn’t work.
- Fix the code
- Run the app. It works.
We have to run the app at some points to check if the code works as expected. The steps above are one chunk. We repeat this process and face some issues on the way but we haven’t done any commit yet. There are lots of code changes and we need to find out the root cause but it is harder to find it than finding it in a small change. If we do a commit after step 4 above, it’s easy to find the root cause because the code changes are relatively small.
Do commit frequently with small change in local
It sounds cumbersome for some people to commit frequently but it’s definitely a good habit to develop faster. Let’s consider adding the following Feature1.
Feature 1 class1 function1-1 --> commit
function1-2 --> commit
function1-3 --> commit
class2 function2-1 --> commit
function2-2 --> commit
function2-3 --> commitI do a commit after I complete the implementation for each function. If a function is too small and works for sure, more than two functions can be in a commit, but normally, there will be more than 6 commits because refactoring commits can also be included. It is also good to commit more frequently if you think the code change is a meaningful chunk. With these small commits, we can easily go back to a certain commit if we have some problem. We don’t have to consider seriously about the commit message here because some commits will be put into one commit together. We can change the message later.
When refactoring, there are already unit tests. After the small refactoring, unit tests should be executed to confirm if the code still works. Then, do a commit even if it has not been completed. Repeat the process to complete the refactoring.
Put the related commits into one commit by Squash or Fixup
The local commits history might be messy due to the frequent small commits. It’s ok because we can amend the commit history by git rebase before pushing it. In git rebase, the commit order can also change. If it doesn’t break the code, try it to put some commits into one commit together for clear history.
In the case above, the number of commits is 6 if we consider it based on function. If we consider it based on class, it is 2. I prefer small chunks, so I personally rebase it based on function.
Conclusion
It is a good habit to commit frequently with small chunks. It’s easy to apply the same change to another branch and find a root cause of a bug. To keep a single commit small, we need to focus on one thing at a time. We don’t need extra switching time anymore.


Comments